Uploading Multiple Models to LightTag¶
Check out the video explaining this notebook here
In this tutorial we’ll use four different models to generate suggestions. We’ll then use LightTag’s review feature to compare the models performance, and generate a high precision labeled data set. To showcase the API and techniques, we’ll do this on two distinct datasets, Data from the Federal Register and a collection of politcal tweets.
The models we’ll be using are the Named Entity Recognition components from each of the following:
Stanford CoreNLP running in a docker container (docker run -p 9000:9000 nlpbox/corenlp)
Outline¶
This guide is broken down into a few parts as follows:
First, we write utility functions for each of the models above which run them on our text and return the results in LightTag’s expected format
We’ll pull the datasets we want to process from LightTag and run each of the models on them
We’ll unify the model outputs, since some of them output different names for the same thing (ORG vs ORGANIZATION)
We’ll create a new Schema based on the unified tags
Upload the model suggestions
Review the Data in LightTag
Pull metrics
Part 1 - Adapters for our four models¶
[52]:
from ltsession import LTSession # Thin wrapper over LightTag's api, get it here (https://gist.github.com/talolard/793563397c48dca32f75c9d4b6f8f560)
import spacy
import requests
import pandas
import re
import pandas as pd # We use this to check ourselves
from flair.data import Sentence
from flair.models import SequenceTagger
CoreNLP¶
We’re running CORENLP In a docker container. CoreNLP trims whitespaces and sometimes returns overlapping annotations, so we need to handle those cases
[33]:
preWhiteSpace = re.compile('^\s+')
def stanford_to_lighttag_format(example,ent):
'''
Takes a LightTag example and a stanford entitty and returns a LightTag Suggestion
'''
match = preWhiteSpace.search(example['content'])
offset = match.end(0) if match else 0 #CORENLP strips whitespaces so we use that regex to adjust offsets
start = ent["characterOffsetBegin"] + offset
end = ent["characterOffsetEnd"] + offset
return {
"example_id":example["id"],
"start":start,
"end":end,
"tag":ent["ner"],
"value":example['content'][start:end]
# "tag_id":tagMap[sug["ner"]]
}
# This is the URL of the CORENLP server running in a docker container
url='http://localhost:9000/?properties={"annotators":"ner","outputFormat":"json"}'
def process_with_stanford(example):
'''
Gets a LightTag example, runs coreNLP on it and returns a list of suggestions in LightTag format
'''
results = []
txt = example['content'].encode('utf8') # We need to send it bytes
data = requests.post(url,data=txt,).json() #Send to the container
cursor =-1 # Track the last position of a corenlp annotation, so we can ignore overlapping
for sentence in data['sentences']: #Corenlp does sentence parsing as well, which we dont care about
for entity in sentence["entitymentions"]: #iterate over the entities
sug = stanford_to_lighttag_format(example,entity) #covert stanford entitiy to lighttag format
if sug['start']>cursor: # don't accept overlaps
results.append(sug)
cursor=sug['end']
return results #The list of lighttag suggestions
Spacy Big and Small¶
We’re using two built in NER models from Spacy. It’s a little easier than stanford
[25]:
big_nlp = spacy.load("en_core_web_lg") # Load the big spacy model
small_nlp = spacy.load("en_core_web_sm") #Load the small spacy model
def spacyToSug(example,ent):
return {
"example_id":example["id"],
"start":ent.start_char,
"end":ent.end_char,
"tag":ent.label_,
"value":example['content'][ent.start_char:ent.end_char]
}
def process_with_spacy_big(example):
results = []
doc = big_nlp(example['content'])
for ent in doc.ents:
results.append(spacyToSug(example,ent))
return results
def process_with_spacy_small(example):
results = []
doc = small_nlp(example['content'])
for ent in doc.ents:
results.append(spacyToSug(example,ent))
return results
Flair¶
Zalandos’s Flair package has received many rave reviews and made some big claims. Will be interesting to see how it fares against others Only thing to note is that if you are on CPU, use the ner-fast model, the regular one is very slow
[4]:
ftagger = SequenceTagger.load('ner-fast')
def flair_to_suggestions(example,ent):
return {
"example_id":example["id"],
"start":ent.start_pos,
"end":ent.end_pos,
"tag":ent.tag,
"value":example['content'][ent.start_pos:ent.end_pos]
# "tag_id":tagMap[sug["ner"]]
}
def process_with_flair(example):
doc = Sentence(example['content'])
ftagger.predict(doc)
return [flair_to_suggestions(example,ent) for ent in doc.get_spans('ner')]
2019-10-17 14:53:55,792 loading file /home/tal/.flair/models/en-ner-fast-conll03-v0.4.pt
[18]:
Putting them together¶
Here we write a helper function, that receives a list of examples and process each one with each of the models. We collect the list of example_ids that we have seen and submit a testament for each model,example pair. This tells LightTag that the model saw the example, even if it made no predictions, and then we can give accurate analytics
[45]:
def process_multiple_examples(examples):
models={ # Dictionary of models, each has a list of suggestions
'spacy_big':[],
'spacy_small':[],
'stanford':[],
'flair':[],
}
example_ids = [] # we use this to track which examples have been seen. Later we'll submit a testament to LightTag for each model
for num,example in enumerate(examples):
models['spacy_big']+=(process_with_spacy_big(example))
models['spacy_small']+=(process_with_spacy_small(example))
models['flair'] += (process_with_flair(example))
models['stanford'] +=(process_with_stanford(example))
example_ids.append(example['id']) # Take note of the example_id we just processed
if num %10 ==0:
print(num)
return {'models':models,'example_ids':example_ids}
Part 2 Get The Data From LightTag¶
We’ve already uploaded the data to our LightTag workspace, but if you’d like to follow along on yours, you can find the raw data here The important point here, is that you pull the data from your LightTag worksapce so that you have the example_ids
[21]:
session = LTSession(workspace='demo',user='lighttag',pwd='Shiva666') # Start an API session
[62]:
fed_reg_examples =session.get('v1/projects/default/datasets/fedreg/examples/').json() #Retreive the examples from the fedreg dataset
trump_examples =session.get('v1/projects/default/datasets/tweets/examples/').json() # Retreive the examples from the tweeets dataset
examples = fed_reg_examples[:250] + trump_examples[:250] #We take a subset because Flair is slow
[23]:
len(fed_reg_examples),len(trump_examples),len(examples)
[23]:
(1818, 6444, 8262)
[63]:
#Run all of the models on the data
result_dict = process_multiple_examples(examples)
0
10
20
30
40
50
60
70
80
90
100
110
120
130
140
150
160
170
180
190
200
210
220
230
240
250
260
270
280
290
300
310
320
330
340
350
360
370
380
390
400
410
420
430
440
450
460
470
480
490
[64]:
# This is what the results look like
model_outputs = result_dict['models']
model_outputs['stanford'][0]
[64]:
{'example_id': '40e46279-6602-4d97-bf61-66878d565d1d',
'start': 4,
'end': 23,
'tag': 'MISC',
'value': 'Trade Agreement Act'}
Part 3 - Normalizing the Output¶
We ran different models, and while all of them do “NER”, they use different terms and different granularities. In order to compare them, we need to normalize the tags they use which is what we do below. We make a dictionary that maps from the tag we want to replace to it’s replacement value, then iterate over the suggestions and apply it when necasary
[65]:
maper_dict = dict(ORGANIZATION='ORG',CARDINAL='NUMBER',LOCATION='GPE',LOC='GPE',COUNTRY='GPE',STATE_OR_PROVINCE='GPE',
NATIONALITY='NORP',WORK_OF_ART='MISC',CITY='GPE',IDEOLOGY='NORP',PER='PERSON',ORDINAL='NUMBER',
PRODUCT='MISC',RELIGION='NORP'
)
replace_if_need = lambda tag: maper_dict.get(tag,tag) #if the tag is in the dict, give its replacement, otherwise keep it
def normalize_suggestion(suggestion):
suggestion['tag'] = replace_if_need(suggestion['tag'])
return suggestion
for model_name in model_outputs:
model_outputs[model_name] =list(map(normalize_suggestion,model_outputs[model_name]))
Checking ourselves¶
[66]:
AllSuggestions = pd.DataFrame()
for model_name in model_outputs:
suggestions_pd = pd.DataFrame(model_outputs[model_name])
suggestions_pd['model'] = model_name
AllSuggestions = AllSuggestions.append(suggestions_pd)
It’s really useful to look at a pivot table of the tags vs models, counting how often each model said each tag. This tells us nothing about who did a better job, but it can help us recognize overlapping tag names or tags we might not care about
[68]:
AllSuggestions.pivot_table(index='model',columns='tag',values='start',aggfunc=len).fillna(0).T
[68]:
| model | flair | spacy_big | spacy_small | stanford |
|---|---|---|---|---|
| tag | ||||
| CAUSE_OF_DEATH | 0.0 | 0.0 | 0.0 | 7.0 |
| CRIMINAL_CHARGE | 0.0 | 0.0 | 0.0 | 3.0 |
| DATE | 0.0 | 335.0 | 332.0 | 398.0 |
| DURATION | 0.0 | 0.0 | 0.0 | 32.0 |
| EVENT | 0.0 | 6.0 | 15.0 | 0.0 |
| FAC | 0.0 | 7.0 | 25.0 | 0.0 |
| GPE | 351.0 | 565.0 | 563.0 | 596.0 |
| HANDLE | 0.0 | 0.0 | 0.0 | 90.0 |
| LAW | 0.0 | 239.0 | 164.0 | 0.0 |
| MISC | 490.0 | 51.0 | 97.0 | 257.0 |
| MONEY | 0.0 | 58.0 | 43.0 | 31.0 |
| NORP | 0.0 | 52.0 | 56.0 | 71.0 |
| NUMBER | 0.0 | 585.0 | 608.0 | 846.0 |
| ORG | 726.0 | 1013.0 | 1012.0 | 552.0 |
| PERCENT | 0.0 | 19.0 | 25.0 | 24.0 |
| PERSON | 130.0 | 175.0 | 184.0 | 207.0 |
| QUANTITY | 0.0 | 1.0 | 1.0 | 0.0 |
| SET | 0.0 | 0.0 | 0.0 | 20.0 |
| TIME | 0.0 | 26.0 | 21.0 | 17.0 |
| TITLE | 0.0 | 0.0 | 0.0 | 121.0 |
| URL | 0.0 | 0.0 | 0.0 | 138.0 |
Part 4 - Defining a New Schema¶
In case we don’t already have a Schema defined in LightTag that contains all of these tags, we can create one now with the API. We’ll take a list of the tags that appeared from the dataframe we just calulated, then define a new schema
[70]:
tags=AllSuggestions.tag.unique().tolist()
[73]:
schema_def = {
'name':'ner-model-comparison',
'tags':[{'name':t,'description':t } for t in tags]
}
new_schema =session.post('v1/projects/default/schemas/bulk/',json=schema_def)
[74]:
schema_id = new_schema.json()['id']
[75]:
[75]:
11385
Part 5 - Registering the models and uploading suggestions.¶
As we saw before we need to register a model before we can upload suggestions to it. Models belong to a schema, like the one we just defined. In this example, we’ll iterate over the models we calculated and register them, upload suggestions and submit testaments in one go
[77]:
registerd_models = {} # Capture the models we registered already
for model_name in model_outputs:
model_def = { #definition of the model
'schema':schema_id,
'name':model_name,
'metadata':{
'anything':['you','want']
}
}
response = session.post('v2/models/',json=model_def) # Send it to LightTag
model = response.json() # Get back the model we just regitered
registerd_models[model_name] = model #Store it for later
session.post(model['url']+'suggestions/',json=model_outputs[model_name]) #Send the suggestions
session.post(model['url']+'testaments/',json=result_dict['example_ids']) # Testaments, tells LightTag all of the examples this model has seen
Part 6 - Reviewing The Results In LightTag¶
Now that our suggestions have been uploaded, we want to know how our models compare to each other. We can get a rough sense by looking at the Inter Model Agreement in LightTag’s analytics dashboard. But agreement isn’t enough we want to know who was right and who was wrong, and we’ll use LightTag’s review feature for that
Inter Model Agreement¶
A quick way to see if our models tend to agree or conflict. In our case, looks like lots of disagreement. 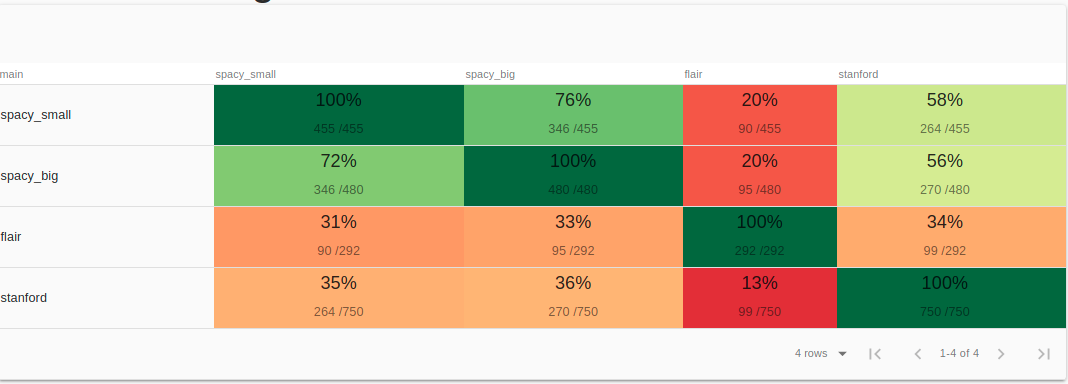
Inter Model Agreement API¶
Review¶
Still the question remains, are any of these models better than others ? Do they perform differently on the two datasets ? Only one way to find out, by reviewing the data. Luckily LightTag makes this easy with Review Mode
[87]:
IMA = session.get("/v1/metrics/model/iaa/",params={"schema_id":schema_id}).json()
IMA = pd.DataFrame(IMA)
IMA.head()
[87]:
| dataset | id | model_x | model_y | num_agree | schema | size | |
|---|---|---|---|---|---|---|---|
| 0 | 42d4181d-934f-4c58-850d-ecdf6fdeb830 | 62f92ec5-8ae5-4843-aa16-99a638360dc5/62f92ec5-... | 62f92ec5-8ae5-4843-aa16-99a638360dc5 | 62f92ec5-8ae5-4843-aa16-99a638360dc5 | 2691 | f46c639f-7359-4978-9104-62d23b20656d | 2691 |
| 1 | 8f5bd425-ae8c-45f2-9cdd-f297ae6a5806 | 62f92ec5-8ae5-4843-aa16-99a638360dc5/62f92ec5-... | 62f92ec5-8ae5-4843-aa16-99a638360dc5 | 62f92ec5-8ae5-4843-aa16-99a638360dc5 | 455 | f46c639f-7359-4978-9104-62d23b20656d | 455 |
| 2 | 42d4181d-934f-4c58-850d-ecdf6fdeb830 | 62f92ec5-8ae5-4843-aa16-99a638360dc5/96f8d8a1-... | 62f92ec5-8ae5-4843-aa16-99a638360dc5 | 96f8d8a1-7e00-4ba8-b806-76ae745bf13e | 1881 | f46c639f-7359-4978-9104-62d23b20656d | 2691 |
| 3 | 8f5bd425-ae8c-45f2-9cdd-f297ae6a5806 | 62f92ec5-8ae5-4843-aa16-99a638360dc5/96f8d8a1-... | 62f92ec5-8ae5-4843-aa16-99a638360dc5 | 96f8d8a1-7e00-4ba8-b806-76ae745bf13e | 346 | f46c639f-7359-4978-9104-62d23b20656d | 455 |
| 4 | 42d4181d-934f-4c58-850d-ecdf6fdeb830 | 62f92ec5-8ae5-4843-aa16-99a638360dc5/b24cf488-... | 62f92ec5-8ae5-4843-aa16-99a638360dc5 | b24cf488-8b83-4766-b6cd-cee6afac2fe7 | 353 | f46c639f-7359-4978-9104-62d23b20656d | 2691 |